transformer
以注意力取代循环,提升并行与长距依赖建模;概述核心机制、训练要点与长序列改进的实践建议。
为什么是 Transformer
RNN 在长序列上存在梯度消失与并行度低的问题;CNN 捕获长距依赖需要更深的网络和更大的感受野。Transformer 用注意力直接建模任意位置间的关系,并且完全抛弃循环,使训练与推理更易并行,成为 NLP 与多模态的主力结构。
核心积木
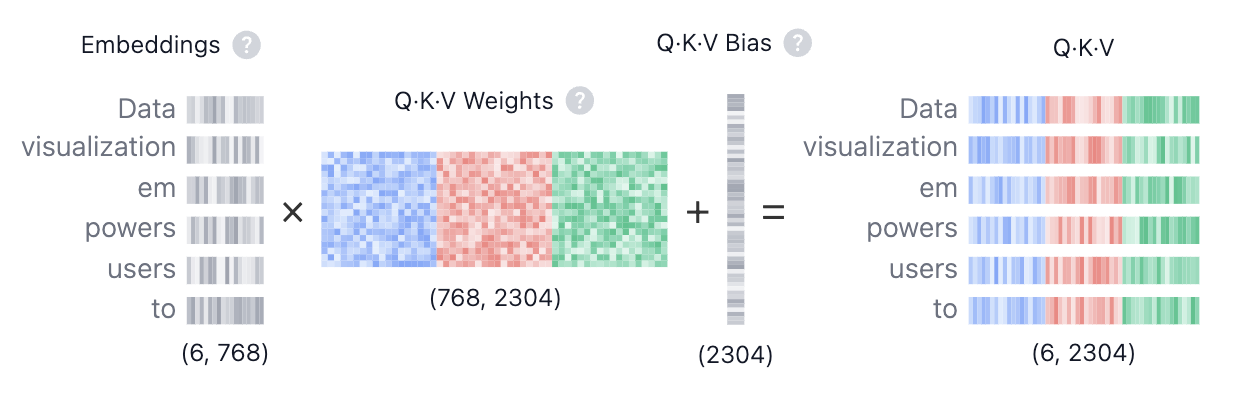
“核心积木”指构成 Transformer 的基础模块集合,这些模块按层堆叠并组合成编码器/解码器,实现并行的长距依赖建模。主要包括:Scaled Dot-Product Attention、Multi-Head Attention、前馈网络(Feed-Forward Network,FFN)、残差连接与层归一化(LayerNorm)、位置编码。
Scaled Dot-Product Attention
给定 Q、K、V,注意力是:softmax(QK^T / sqrt(d_k)) V。其中 1/sqrt(d_k) 用于数值稳定,避免在大维度上点积过大导致 softmax 过于尖锐。
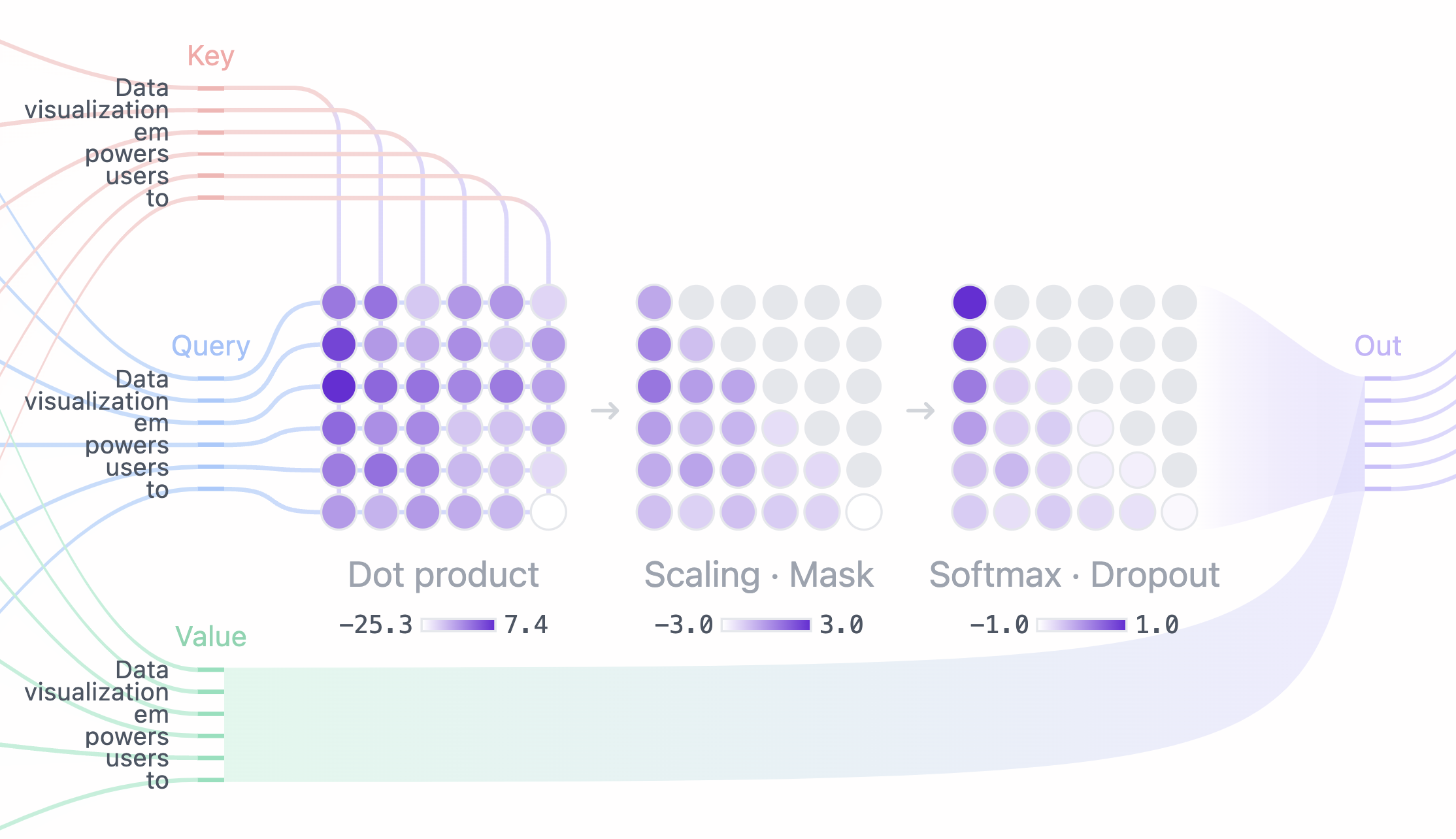
这里有一个trick就是掩码,掩码的目的就是为了不让词语预测时候窥见位置比它更靠后的词语
Multi-Head Attention
将 Q/K/V 线性映射到多个子空间并行计算注意力,再拼接回去。多头让模型在不同投影下关注不同的关系模式(位置、语义、语法等)。
其实就是每个token通过不同attention计算出来的输出再把这些输出concate起来
前馈网络(Feed-Forward Network)
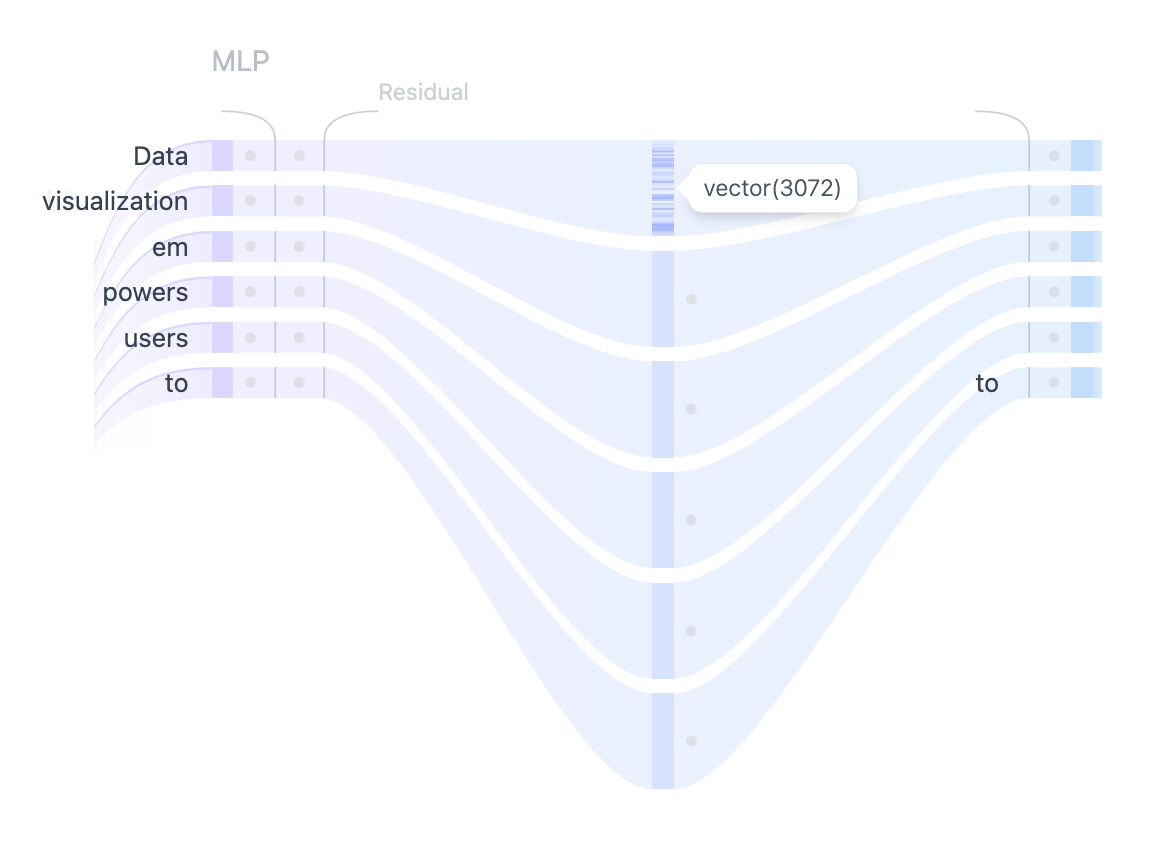
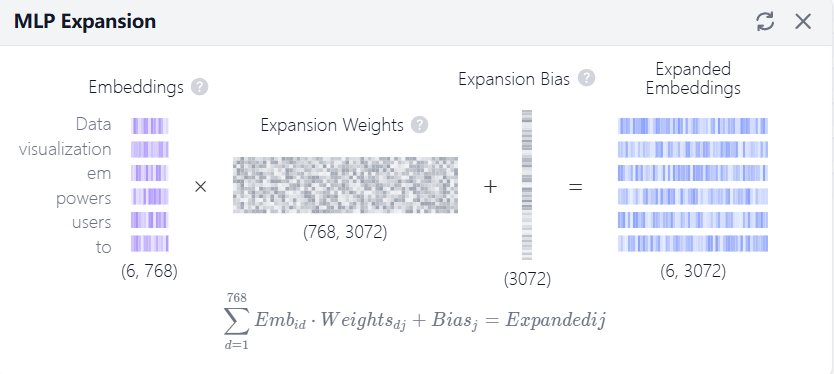
残差与层归一化
在 GPT-2 中,每个 Transformer 模块内都使用了两次残差连接:一次在多层感知器 (MLP) 之前,一次在之后,确保梯度能够更顺畅地传递,并且前面的层在反向传播过程中能够获得足够的更新。
输出层
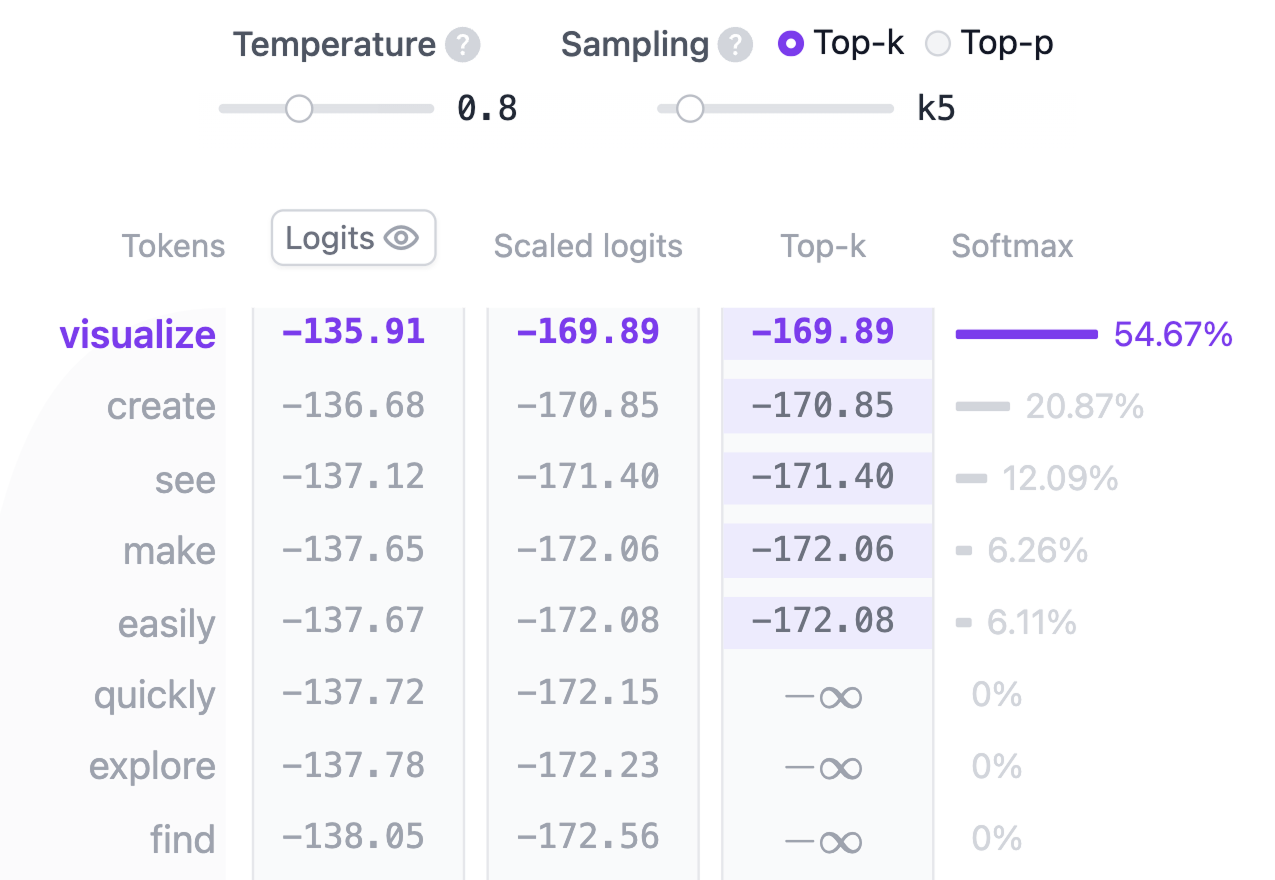
- top-K方式代表把概率前K个进行softmax归一变换
- top-P方式代表把概率前P个进行softmax归一变换
最后预测的token并不是概率最大的那个输出,而是按照概率抽样输出,因此温度值的作用就体现在这里,温度值能够影响输出更具有创新性还是更确定
模型输出的logits只需除以该超参数即可 temperature。
- temperature = 1将 logits 除以 1 对 softmax 输出没有影响。
- temperature < 1较低的温度通过锐化概率分布,使模型更加自信和确定,从而产生更可预测的输出。
- temperature > 1较高的温度会产生更柔和的概率分布,从而允许生成的文本具有更大的随机性——有些人称之为模型的“创造力”。
位置编码
序列没有循环结构,需要显式注入位置信息。可用正弦位置编码(原论文)或可学习的位置嵌入;也可用相对位置编码增强泛化与长度外推能力。
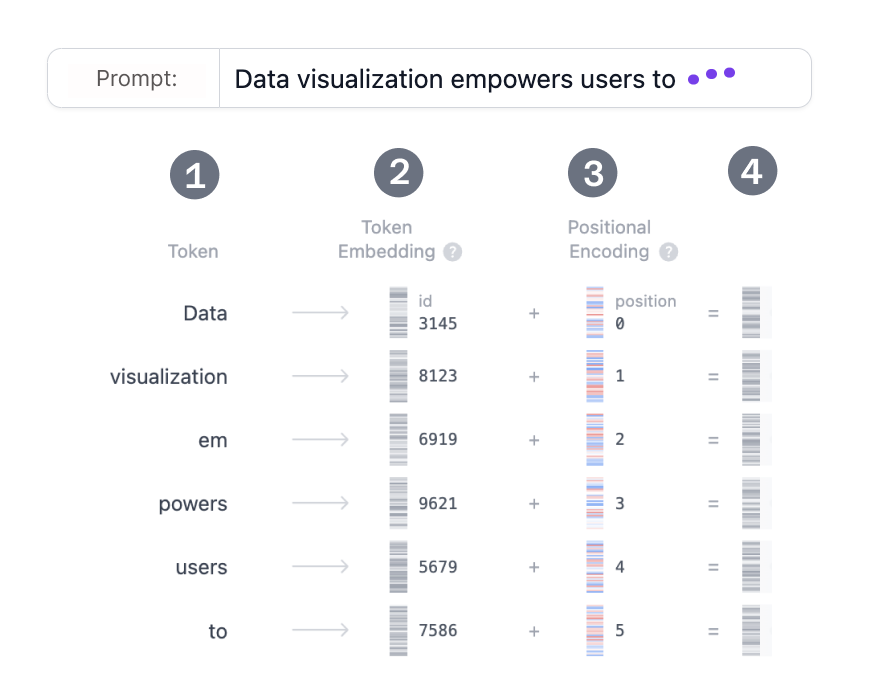
- 位置信息和token embedding一般采用相加形式
编码器与解码器
- 编码器:堆叠自注意力 + 前馈网络,输出上下文表示。
- 解码器:在自回归生成中使用 masked self-attention(只看过去),并用 cross-attention 结合编码器输出,逐步生成目标序列。
训练与推理要点
- 优化器:AdamW 常用,配合学习率预热与衰减(如 cosine)。
- 正则化:Dropout、标签平滑(label smoothing)提升稳健性。
- 长序列复杂度:标准注意力是
O(n^2),可考虑稀疏/低秩/核方法减复杂度。
常见变体与应用
- BERT:双向编码器,用于理解类任务(分类、抽取、检索)。
- GPT:解码器为主的自回归生成(文本生成、对话、代码)。
- T5:统一为 text-to-text 任务,方便多任务迁移。
- ViT:将图像分块为 patch 作为“词”,用纯注意力进行视觉建模。
参考文章
- 可视化/交互式解释器:Transformer Explainer
- 原论文:Attention Is All You Need(2017)